Site search
Search the published MegaCpp archive
Use this page as both a search surface and a discovery map: topic hubs for reading order, term-driven entry points for hard concepts, and the full archive filter underneath.
Start with a reading path
Use the strongest cluster entry points before free-form search
The archive is broad enough that raw keyword search can hide the best entry point. These hubs are the shortest grounded routes into the busiest technical lanes.
Topic hub
GB10 and Blackwell Bring-Up
A curated GB10 and Blackwell reading path: consumer-versus-datacenter tensor paths, driver-visible false positives, arch-patch repros, and the serving or precision choices that survived contact with the hardware.
9 curated in-hub reads
Recent entry point
What Our GB10 Experiments Actually Prove About Blackwell Consumer vs Datacenter Tensor Paths
April 20, 2026
Topic hub
Modal Training and Benchmark Operations
A curated Modal reading path: when the rented-GPU surface was useful, what broke on multi-GPU launches, how receipts were recorded, and how we kept the lane debuggable.
7 curated in-hub reads
Recent entry point
What Our GB10 Experiments Actually Prove About Blackwell Consumer vs Datacenter Tensor Paths
April 20, 2026
Topic hub
Mamba3 Architecture, Kernels, and Runtime Tradeoffs
A curated Mamba3 reading path: why MegaCpp kept a hybrid stack, how the kernels evolved across CUDA, TileLang, and TPU, and where the runtime wins actually held.
11 curated in-hub reads
Recent entry point
What Our GB10 Experiments Actually Prove About Blackwell Consumer vs Datacenter Tensor Paths
April 20, 2026
Topic hub
MLA Integration, Dispatch, and Weight Absorption
A curated MLA reading path: the weight-absorption contract, Megatron-safe integration boundaries, dispatch and FP8 edges, and the adapter surfaces that keep MLA connected to the rest of the stack.
9 curated in-hub reads
Recent entry point
What Our GB10 Experiments Actually Prove About Blackwell Consumer vs Datacenter Tensor Paths
April 20, 2026
Topic hub
Evaluation, Benchmarks, and Verifier Loops
A curated evaluation reading path: verifier-first harnesses, ablation structure, benchmark receipts, and the evidence rules that keep comparisons from collapsing into anecdotes.
12 curated in-hub reads
Recent entry point
What Our GB10 Experiments Actually Prove About Blackwell Consumer vs Datacenter Tensor Paths
April 20, 2026
Topic hub
Megatron Parallelism and Layout Boundaries
A curated Megatron reading path: the parallelism map, what actually splits, how NVIDIA and TPU wrappers differ, and the migration surfaces around NAM56R-style layouts.
9 curated in-hub reads
Recent entry point
What Our GB10 Experiments Actually Prove About Blackwell Consumer vs Datacenter Tensor Paths
April 20, 2026
Topic hub
TPU Sparse Attention and Pallas Kernels
A curated TPU sparse-attention reading path: block-sparse contracts, Pallas kernel choices, SPMD sharding, and the runtime surfaces that keep long-context TPU work stable.
9 curated in-hub reads
Recent entry point
What Our GB10 Experiments Actually Prove About Blackwell Consumer vs Datacenter Tensor Paths
April 20, 2026
Topic hub
H200 Training and Kernel Bring-Up
A curated path through the H200 lane: operator bring-up, step-time anatomy, memory pressure, and the NVIDIA kernel surfaces that actually moved the stack.
15 curated in-hub reads
Recent entry point
What Our GB10 Experiments Actually Prove About Blackwell Consumer vs Datacenter Tensor Paths
April 20, 2026
Grounded term entry points
Jump from a technical term to the right part of the corpus
These shortcuts are for concepts that show up across the blog but usually need one strong starting document or hub instead of a generic results list.
tcgen05
GB10 / Blackwell proof lane
Tensor-path proofs, `sm_100a` versus `sm_121a`, and the point where tcgen05 evidence stops.
Cross-link: Start with the proof summary
PJRT
TPU/XLA ownership boundaries
libtpu, PJRT, JAX, and Torch/XLA ownership splits with checked-in examples and receipts.
Cross-link: Broader TPU/XLA hub
FSDP2
Megatron and wrapper boundaries
Parallelism surfaces, wrapper seams, and migration paths once FSDP2 enters the stack.
Cross-link: Open the Megatron reading path
Mamba3
Mamba3 architecture and kernels
Hybrid-model rationale, kernel evolution, and cache scaffolds in one reading order.
Cross-link: Model contract first
MLA
MLA systems and dispatch
Weight absorption, adapter boundaries, sparse dispatch, and cache-side consequences in one path.
Cross-link: Architecture-first article
Verifier loop
Evaluation and benchmark evidence
Verifier-first evals, ablation structure, benchmark receipts, and profiler-backed comparisons.
Cross-link: Verifier-first starting point
TileLang
TileLang and TMA reality checks
Blackwell and H200 kernel experiments, TMA bulk-copy constraints, and what survived testing.
Cross-link: Related NVIDIA kernel lane
compile_commands.json
C++ data and semantic indexing
C++ corpus construction, semantic graphs, compile database inputs, and indexed dataset preparation.
Cross-link: Data-pipeline hub
Filter the full archive
Browse the archive
Filter by topic and search the published notes
Narrow the blog by feature family, runtime surface, or keyword.
Need a guided path?
Use the topic hubs for short reading orders across the H200, TPU/XLA, data-pipeline, and MoE lanes.

What Our GB10 Experiments Actually Prove About Blackwell Consumer vs Datacenter Tensor Paths
Our GB10 tests show that some Blackwell datacenter-targeted SASS can be accepted and executed on consumer silicon, but they do not prove that the Blackwell Tensor Core Generation 5 matrix-instruction path (tcgen05.mma) physically executes on GB10. Older stronger claims overstate what the evidence supports.

Why Driver-Visible Paths Can Look Like Hardware Support on GB10, Even When Silicon Proof Is Missing
A field report on GB10 reverse engineering: how libcuda tables, helper cubins, and signed capability metadata can make tcgen05 look reachable from software while still falling short of proving that the underlying silicon really exposes the same path as B200 or GB100.

Inside the GB10 Driver Patch Lane: libcuda Tables, Helper Cubins, Linux Hooks, and Why Deeper Patching Still Is Not tcgen05 Proof
A public-safe walkthrough of the deeper GB10 driver research lane: what was patched in libcuda, what changed in the cubin and toolchain path, where Linux- and loader-level hooks entered the picture, and why that deeper progress still stops short of publication-grade tcgen05 proof.

Reproducing the sm_100a -> sm_121a Cubin Patch on GB10: CUDA/C++ Code, ELF Edits, and the Exact Point Where tcgen05 Stops
A practical GB10 reproduction guide for the narrow result we can defend publicly: a patched sm_100a baseline cubin executes on GB10, while tcgen05-oriented probes stop at later driver-side gates rather than producing a publication-grade tcgen05 proof.

Author Mamba3 spec inside Megatron
Why an author-pure Mamba3 path still needs an explicit pre-projection RMSNorm when it is wrapped into a Megatron-local Mamba stack.

Clustered sparse on TPU: the planner stages
How MegaCpp decomposes clustered sparse TPU attention into planner stages, legality checks, and backend dispatch rather than treating sparse attention as one giant kernel.

Converting parquet token shards into Megatron indexed datasets
Why MegaCpp keeps a narrow data bridge from tokenized parquet shards to Megatron indexed datasets instead of tying data preparation to one runtime import surface.

DSA and CUDA graph safety
Why DSA index mask updates need branchless graph-capture-safe logic, and why small host-sync accidents can break an otherwise valid CUDA graph path.

DSA CUDA graph safety deep dive
A deeper reproducer-driven look at why DSA index mask updates break CUDA graph capture, and how a branchless fix preserves the same eager semantics.

DSA index-cache patch
Why caching sparse top-k indices across selected DSA layers is not just a speed trick, and why the shared path has to fail closed back to a full layer when no valid cache is available.

DSA indexer memory fix
Why MegaCpp replaces a memory-hungry DSA score path with a fused top-k scoring surface and treats that change as a systems fix, not just a kernel tweak.

DSA indexer memory fix deep dive
A reproducer-driven look at how a fused DSA score path avoids a large upstream-style intermediate while preserving the same output contract.

Fail-closed hybrid pattern translation
Why MegaCpp refuses to silently remap unsupported hybrid block families when translating NAM56R-style patterns into Megatron-native plans.

GateSkip and FlexiDepth after the router
How MegaCpp treats dynamic-depth features as bookkeeping and wiring problems after the router, not just as a paper-level skipping idea.

GB10 Stack Parity for MegaCpp: Torch 2.13 cu132, GCC 15, CUDA 13.2, and the Nightly Constraint
Why MegaCpp mirrored the GB10 software stack so exactly: PyTorch 2.13 cu132 nightly, GCC 15, CUDA 13.2, rebuilt source dependencies, and the device-specific constraints that made parity operational rather than cosmetic.

How to express a Nemotron-style recipe as pure Megatron CLI
Why MegaCpp keeps high-level recipe objects and then lowers them into a smaller native Megatron flag surface instead of treating one giant launcher as the source of truth.

libtpu, PJRT, JAX, and ownership boundaries
Why a shared TPU substrate still leaves distinct ownership lines across PJRT, torch_xla, JAX, and libtpu, and where the main failure boundaries appear in practice.

Liger FLCE reduction=none
Why Liger fused linear cross entropy can go wrong on the reduction='none' backward path, why mean stays correct, and how the scaled-mean workaround restores the intended sum contract.

Mamba linear CE parity deep dive
Why output-layer swaps in Mamba-style stacks need explicit CE parity checks, not just shape compatibility checks.
Mamba3 MIMO 3D-to-2D shared-memory deep dive
Why some Mamba3-style kernels need an explicit 3D-to-2D shared-memory legality rewrite before the backend will accept the tile layout.

Mamba3 PsiV cache scaffold
Why the Mamba3 PsiV cache path is published as a scaffold with a fail-closed gate instead of a silent fallback.

Megatron bin/idx pipeline from parquet token shards
Why a parquet-to-binidx bridge matters, what contract it has to preserve, and why a thin formatting wrapper is worth keeping separate from the low-level converter.

Megatron FLCE on Hopper
Why Hopper-ready fused linear cross entropy is an output-layer contract as much as a kernel choice, and why shape-compatible alternatives are not enough.

Migration policy: native Megatron vs narrow custom seams
Why MegaCpp ports only what Megatron or Nemotron do not already provide, and why ambiguous mappings should fail closed instead of being reinterpreted silently.

NAM56R launch policy
Why a NAM56R launcher is more than translated Megatron arguments, and why runtime policy has to stay explicit alongside the pattern plan.

NAM56R Megatron translation
Why translating NAM56R into Megatron-native syntax is a fail-closed planning step, not a blind string rewrite.

Packed rows as the real training contract
Why packed rows are the real boundary between the data pipeline and the model, and why MegaCpp treats row packing as a schema contract rather than a storage detail.

Protobuf, the 2 GB Wall, and Why MegaCpp Prefers Shards Over Giant Messages
Why large-message serialization becomes fragile near protobuf's practical limits, and how MegaCpp's checkpoint and data paths avoid single huge payloads by using sharded files, streaming conversion, and explicit completion markers.

Public MLA integration patterns for Megatron
How MegaCpp keeps MLA-specific compatibility logic behind a narrow adapter seam instead of scattering it through the whole builder path.

Regional compile without losing the plot
Why MegaCpp treats regional compile as a runtime-boundary decision rather than a blanket switch, and how compile ordering stays tied to distributed and CUDA-graph reality.

Restoration without git history
How MegaCpp reconstructs a Megatron training tree when the code survives but the original commit graph does not.

Restoring a Megatron training tree without git history
How MegaCpp treats restoration as a base-plus-patch-plus-canary workflow when the working tree survived but the original .git metadata did not.
Shared MLA adapter boundaries
Why MegaCpp keeps MLA-specific normalization behind one shared adapter seam instead of leaking MLA conditionals through the whole attention builder stack.

Sparse MLA dimension generalization
Why SparseMLA kernels that hardcode DeepSeek-sized dimensions fail to scale down cleanly to NAM56R-style shapes, and what a generalized contract changes.

Sparse MLA FP8 dispatch
Why SparseMLA needs an FP8-aware dispatch contract when Transformer Engine wrappers hide FP8 storage behind a bf16-looking logical surface.

TileLang TMA and H200 reality
Why TileLang shared-memory legality and TMA lowering on Hopper-class GPUs should be treated as concrete compiler contracts rather than assumed backend magic.

TileLang TMA bulk-copy 3D shared-memory deep dive
A deeper reproducer-driven look at why TileLang TMA bulk-copy paths can fail on shared-memory layout legality before the math is even the problem.

Torch 2.13 on GB10: the serving and training stack we actually chose
A public, evidence-based write-up of the stack choices around Torch 2.13, CUDA 13.2, GCC 15, GB10, and vLLM compatibility in the MegaCpp workflow.

Torch 2.12 TPU/XLA breakage matrix: wheel pain, cache misses, and the workarounds that actually mattered
A repo-grounded account of where the TPU/XLA stack broke, which failures needed upstream-facing patches, and which ones were better handled as explicit MegaCpp runtime policy.

Torch/XLA 2.11 expectations vs TPU reality
What MegaCpp expected from the Torch/XLA 2.11 line on TPU, what the shipped stack actually looked like in practice, and how that changed our bringup strategy.

vLLM on GB10: the overlay, the registration fixes, and the paths we kept off
How MegaCpp stabilized a GB10-oriented vLLM lane with an on-disk overlay, text-only model registration, and a deliberate keep-disabled list for serving paths that were not yet honest.

What changed after the 10K-step gate: the ablations that stayed honest
A grounded reading of training changes after the configured 10K-step gate: STP activation, auxiliary-head timing, plasticity scheduling, and why later ablations are more trustworthy than warmup-era receipts.
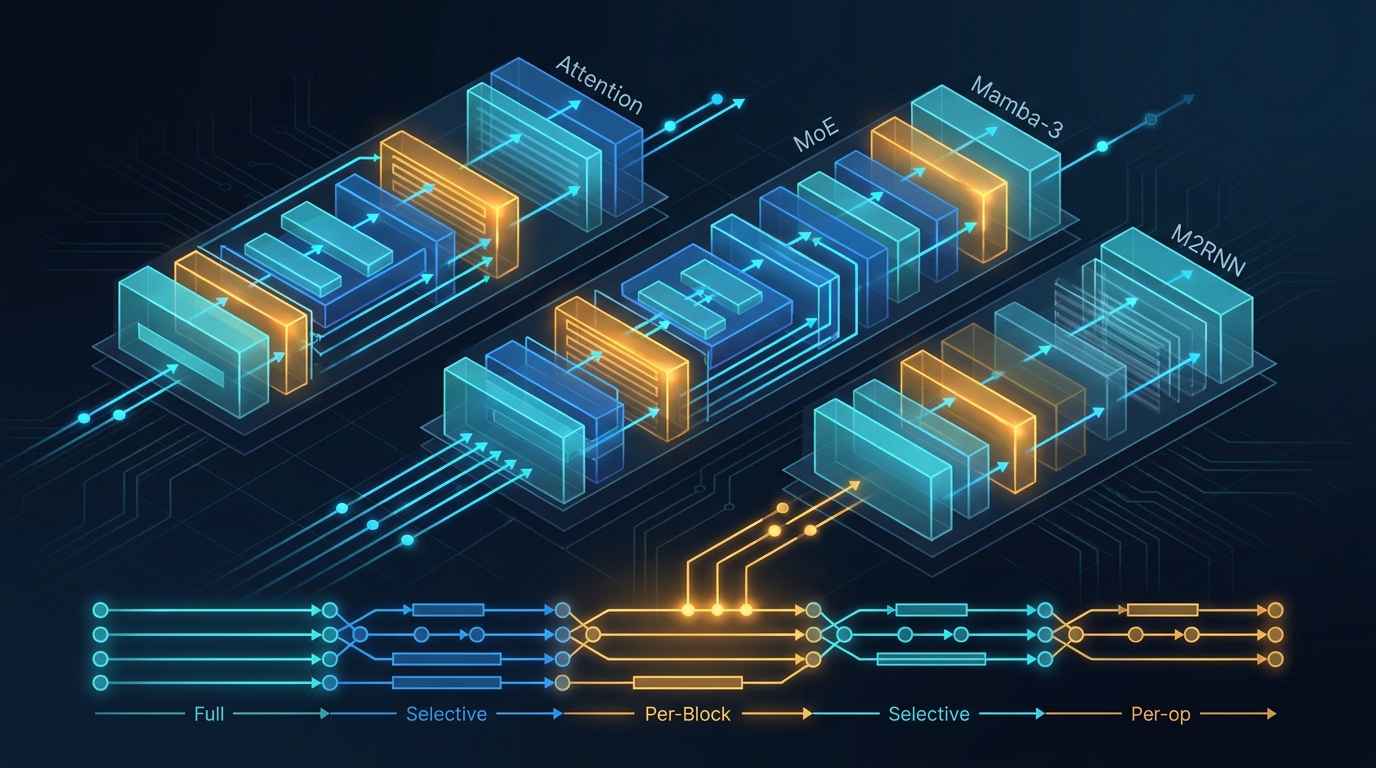
Activation checkpointing deep dive: why per-block policies beat one global switch
Full, selective, and narrow recompute across attention, MoE, Mamba-style, and recurrent blocks: what saves memory, what costs too much compute, and why a per-block policy usually wins.
Activation Checkpointing Policy: The Per-Block Pareto That Held Up
Selective versus full activation checkpointing across attention, MoE, Mamba-style, and recurrent blocks, and why the best policy depends on where each block actually spends memory and compute.
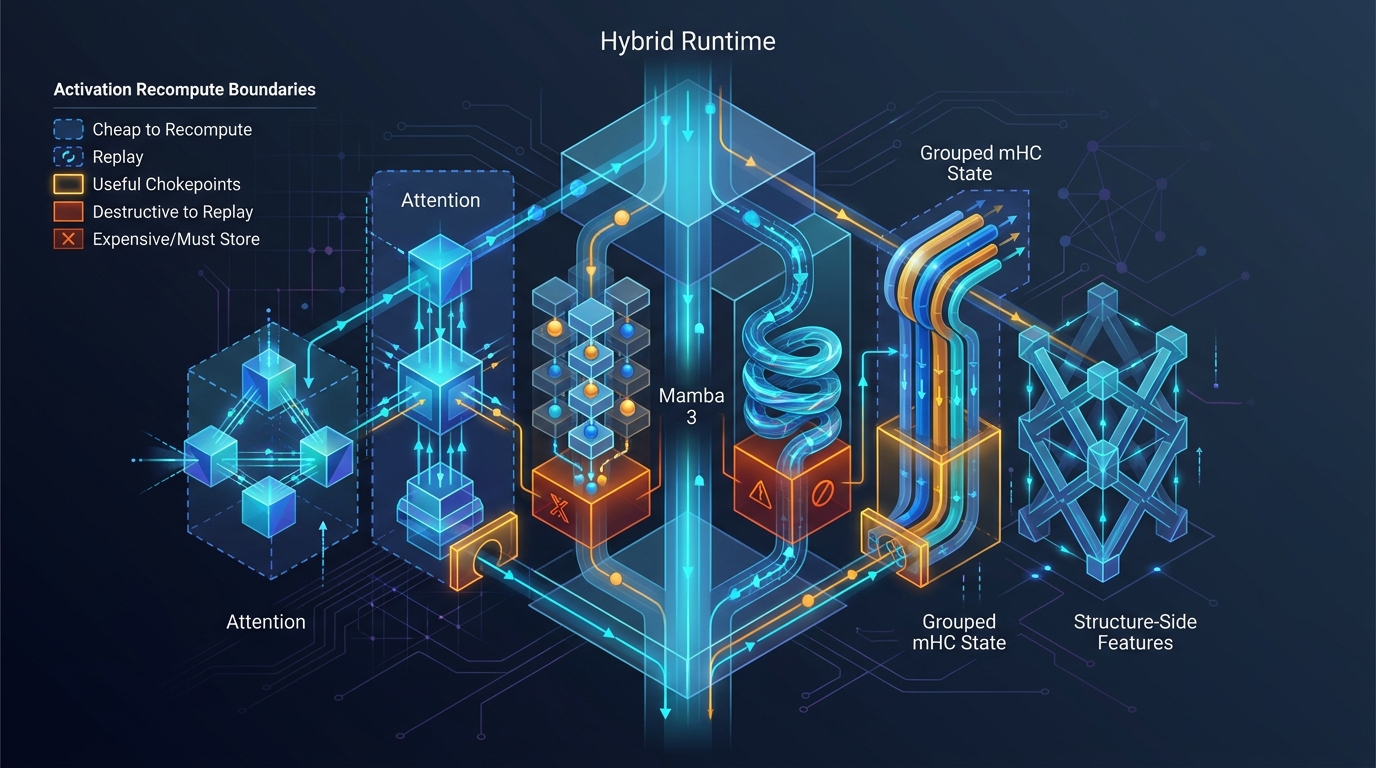
Activation Recompute Boundaries in Hybrid Stacks
Why selective recompute has to align with module boundaries, communication edges, and graph-safe surfaces in hybrid training systems.

Activations and how we split them
What activations actually are in a hybrid Mamba 3, Transformer, and MoE stack, why they dominate memory at long context, and the levers we have: selective recompute per layer or op, sequence parallel, context parallel, and the trade-offs we live with.

The adapter stack: how LoRA, QLoRA, and hot-swap compose MegaCpp specialists
The LoRA, QLoRA, DoRA, VeRA, and DyLoRA family behind MegaCpp specialists, the registry and lifecycle that turn adapters into versioned releases, the hot-swap runtime, and the inference-facing API they power.

Attention sinks and telemetry on TPU: measure without turning observability into the bug
Why TPU telemetry has to be gated carefully: scalar reads can become host-device syncs, so sink and outlier tracking must be designed as explicit low-cadence instrumentation.

Attention Validity and Structure-Aware Attention
A packed-row validity regression, the clustered-sparse follow-up it forced, and the structure-aware attention plan we are integrating into the MegaCpp training stack.
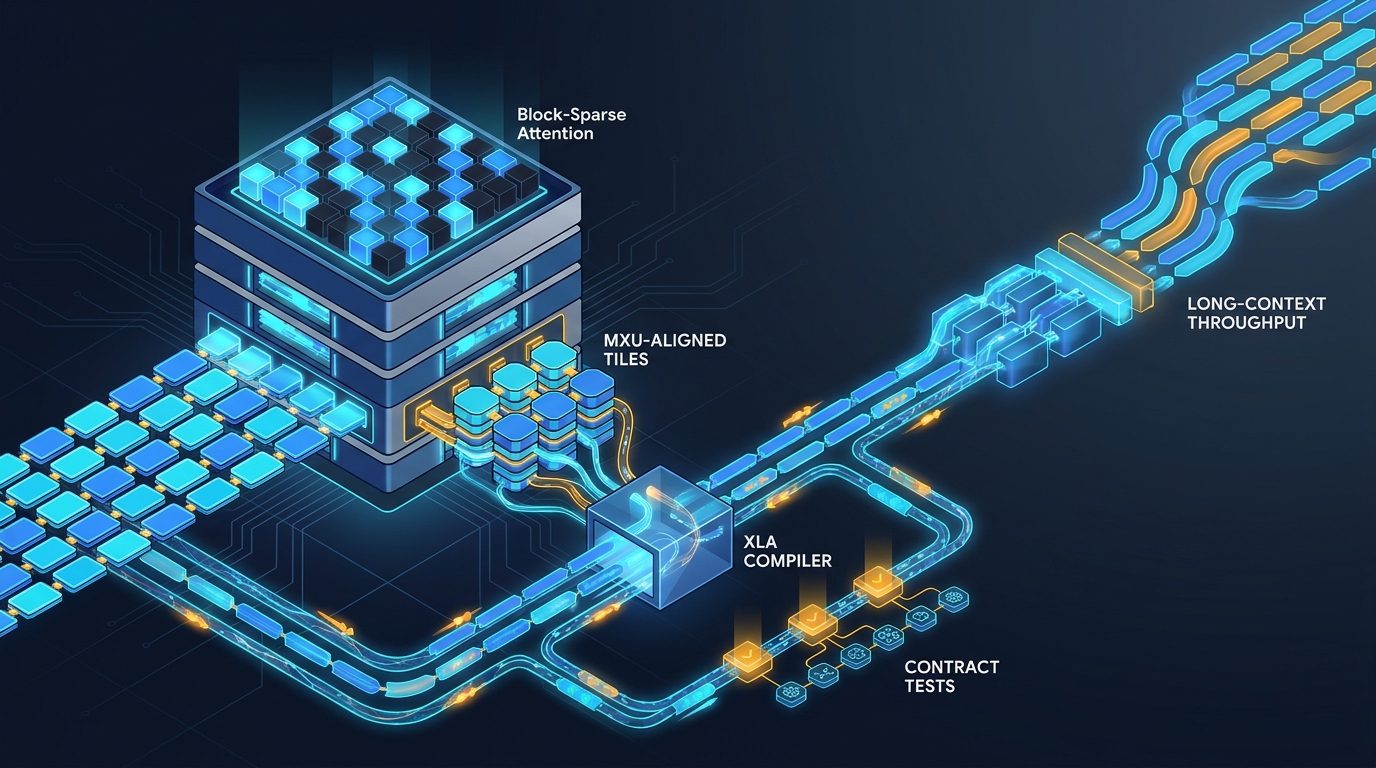
Block-sparse attention on TPU v6e: block masks, MXU-friendly tiles, and stable contracts
How to frame block-sparse attention on TPU honestly: explicit mask contracts, MXU-aligned tile choices, and a preference for stable sparse layouts over data-dependent retracing.
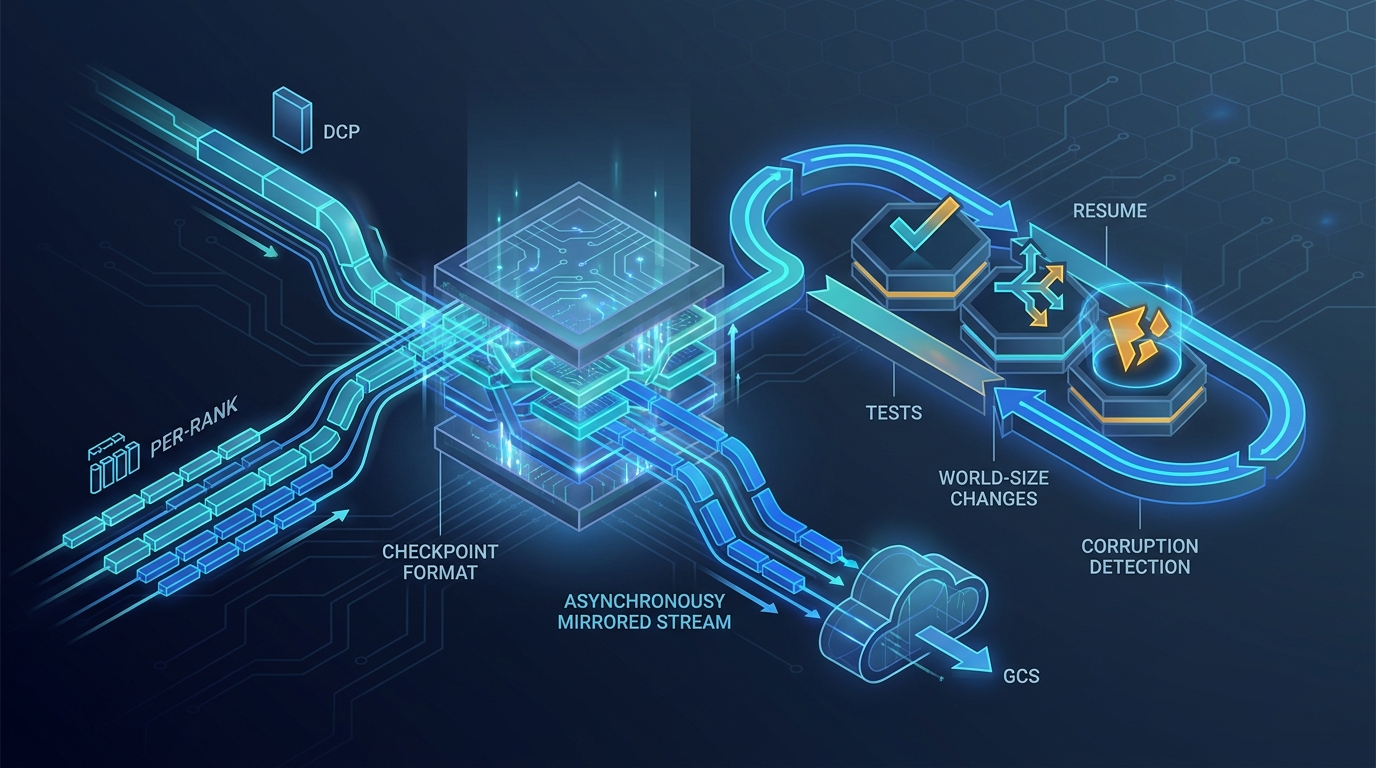
Checkpoint Format and Resume: What We Save, and What We Test
DCP vs per-rank checkpoints, async mirroring to GCS, resume tests, world-size changes on resume, and the corruption classes that need explicit detection.

The Clang semantic indexer: translation units, call graphs, and the perf wall
How the libclang-based semantic indexer feeds v6_enriched parquet: compilation-database handling, the per-file translation-unit graph, call and type edges, the failure modes we hit, and the wall-clock cost of ground-truth semantics.
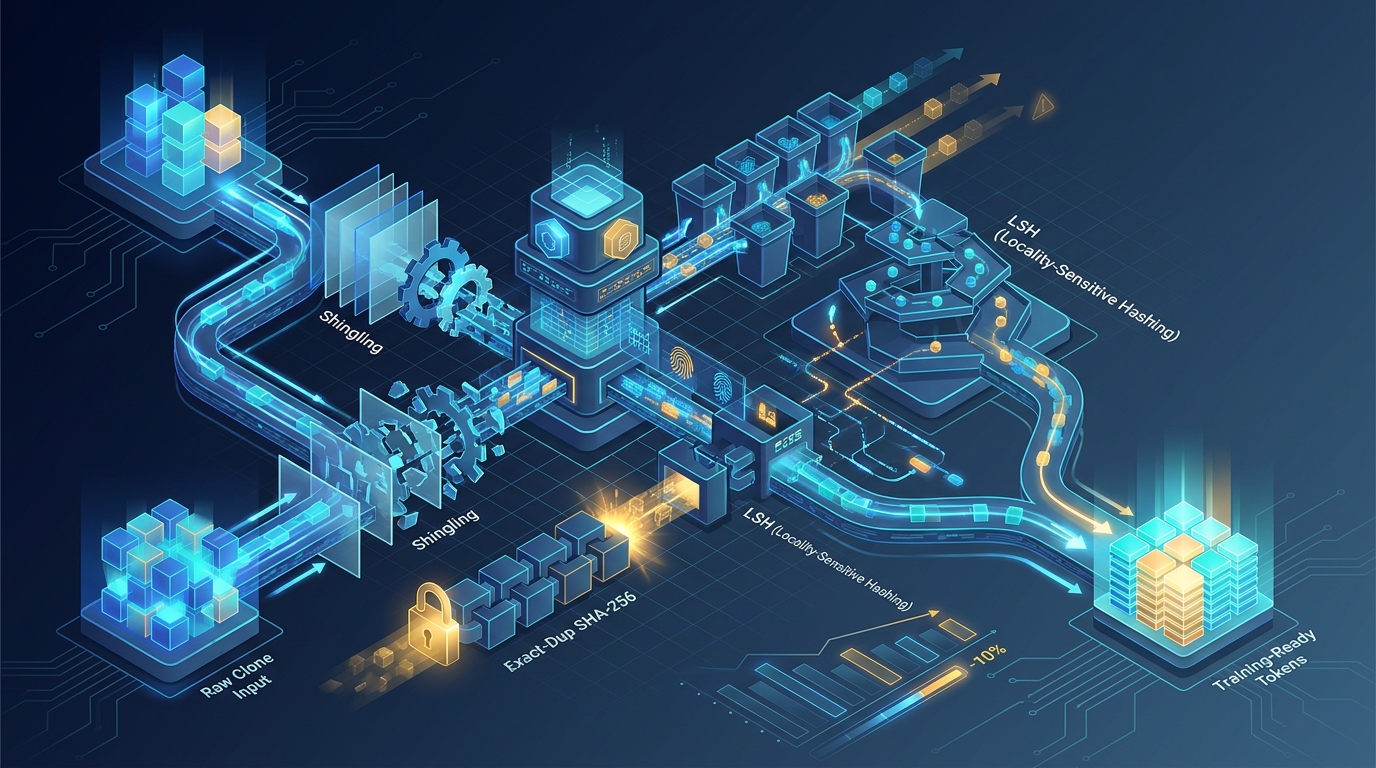
Code Deduplication at Scale: MinHash, LSH, and What a 142-Repo C++ Catalog Actually Looks Like
How MegaCpp deduplicates C++ at scale: shingling choices, MinHash/LSH parameters, exact-dup SHA-256, and the tradeoffs behind near-duplicate removal.

Communication cost and overlap: NCCL on H200, XLA collectives on TPU v6e
How MegaCpp budgets all-reduce, reduce-scatter, and all-gather against compute on the hybrid stack, including bucket sizing, launch coalescing, alignment, and the overlap windows that actually matter.
Compile Commands and Semantic Graphs: Why C++ Training Needs Real Build Context
How compilation-database-driven semantic extraction improves C++ corpus quality, where clang indexers fail, and why build-aware graphs matter more than raw text proximity.

The Compile-Time Tax We Accept for Runtime Speed
Why MegaCpp pays first-compile and recompile costs in exchange for steady-state throughput, and the operational rules that keep torch.compile, torch_xla and Triton caches honest across runs.

Context Parallel and Sequence Parallel: Similar Names, Different Jobs
An explanation of SP versus CP using TP-aware helpers, long-context bring-up patterns, and hybrid model design.

Building a C/C++ corpus for training: what we keep, what we throw away, and why
A detailed walkthrough of how MegaCpp builds a C/C++ corpus: source selection, pins, deduplication, compile-command metadata, chunking, structure-aware exports, and refusal rules.
Data Enhancements: Why structure IDs, AST features, and the Clang graph earn their cost
The structural metadata layered on top of raw C++ source: structure IDs, chunk boundaries, call edges, type edges, tree-sitter AST features, and the optional libclang semantic graph. What each one is for, what the ablations justified, and what we pay in storage and runtime.

The C/C++ Data Preparation Pipeline, End to End
Every stage of the MegaCpp data preparation pipeline: ingest, dedup, license filtering, document masking, tokenization, packed rows, and the checks that keep dataset snapshots trustworthy.

C++ Data Versioning and Schema: How to Keep Training Rows Stable While the Corpus Evolves
Why schema discipline, canonical fallback values, and explicit versioning matter more than format churn when a C/C++ training corpus gains structure-aware metadata.

The C++ Eval Suites, Verifiers, and the Compile-Then-Test Wall
The C++-specific eval surface we actually run: problem sets, the compile-then-test verifier sandbox, header and include coverage, and how per-specialist scorecards fall out of the same harness.

Inside the MegaCpp C++ tokenizer: fixed vocab, BPE, and per-specialist sub-vocabs
A deep look at the tokenizer we ship: half hand-curated vocabulary, half learned BPE, what changed between v2 and v3, where the collisions live, and how per-specialist sub-vocabs fall out of the shared 64K layout.

CPU Offload and Startup Memory Calibration on H200 and GB10
How MegaCpp picks microbatch and offload knobs at boot, the zero-copy pinned offload paths, the AdamW-only optimizer offload trade-offs, and what shipped versus what stayed experimental.

Our honest experience with CuTe DSL
What we tried to build with CuTe DSL, where it held up, where it lost to alternatives, and the chunks we rewrote back to Triton or kept in CUDA.

Building the C++ Training Data Pipeline: What Worked, What Broke
An honest walkthrough of how the MegaCpp training data pipeline was built — source selection, filtering, dedup, tokenization, document masking, and the quality gates that catch our own mistakes.

Data Poisoning Drills and Refusal Behavior for the MegaCpp Specialists
Adversarial data tests, poisoning drills against the C++ specialist ensemble, the refusal behaviors we enforce, and the safety regression layer that sits on top of HumanEval-style code evaluation.

Data Shuffling and Seed Discipline
Deterministic shuffles, seed plumbing across rank and stage, the reshuffle-per-epoch rule, packed-sequence ordering effects on loss curves, and the reproducibility bar we actually hold.

Dataloader throughput and stalls: making the input pipeline a first-class perf concern
Packed-rows schema, prefetch depth, IO budget per step, and the host-side bottlenecks we hit at 64K context — plus the XLA-friendly path that makes the input pipeline boring again.

Dataset Versions v2 to v6: The Long-Form Ablation History
A detailed walk through every schema generation of the C++ training corpus - what each version added, the schema diff, the storage cost, the val_bpb delta we attribute to each step, what we deprecated and why.

v2 to v6: Four Generations of the C++ Dataset, and Why We Kept Them All
What changed between v2, v3, v4, v5, and v6 of the C++ training corpus, why each step happened, why we kept the older formats backwards-compatible, and the val-bpb each one bought us.
Determinism and bit-exact runs: what we guard and where we accept drift
A grounded account of GPU and TPU determinism on our stack: the fast path we run in production, the bitwise path we keep for regression testing, and the tests that fire when silent nondeterminism creeps in.

Distillation, best-of-N, and verifier-grounded RL in the post-training loop
How distillation, best-of-N, GRPO, GSPO, and verifier-grounded reward shaping compose the MegaCpp post-training pipeline: what we ship, what we still iterate, and the RL recipes behind the C++ specialist.

Distributed Optimizer Stress: Drift, All-Gather vs Reduce-Scatter, and Muon Gotchas

Document masking and the curriculum: what to feed each specialist first
Why MegaCpp masks documents inside packed sequences, how the four-phase curriculum runs from 4K syntax to 64K repository graphs, and what the ablations told us about the right starting diet for each specialist.

DualPipe and 3D Parallelism on H200 and GB10
How MegaCpp lays out the TP × PP × DP × EP cube on H200 multi-node systems and GB10, integrates DualPipe / DualPipeV with our hybrid layer pattern, accounts for pipeline bubbles, and launches the deployment training job.

Dynamo and torch.compile Breakage on a Mamba-3 Hybrid
Graph breaks, recompile storms, guard explosions, and cache-hygiene rules we landed while keeping torch.compile useful on MegaCpp's hybrid Mamba-3 + Transformer stack.

EP, PP, TP, CP, SP, DP: The Parallelism Map We Actually Use
What data, tensor, sequence, context, pipeline, and expert parallelism each own, how they compose, and where the real integration risks still live.
How We Evaluate the MegaCpp SLM Ensemble on Real C++ Work
The evaluation design, verifier stack, and release gates we use to measure C++ model quality without collapsing everything into a single leaderboard number.

Eval Harness Plumbing: The Parts That Are Not the Benchmark
The four-axis eval harness plumbing under our C++ benchmarks: sandboxing, compile walls, timeouts, parallel runners, flake isolation, and the contract tests a new benchmark has to pass before it goes into CI.

Expert Parallel and MoE Sharding: Capacity Is Cheap, Routing Is Not
A grounded walkthrough of expert parallelism in the MegaCpp stack, based on the recipe files, layer definitions, schedule plans, and bug reports that shape how MoE runs actually behave.

External library glitches we fixed
A catalog of upstream bugs we hit while training our hybrid Mamba-3 plus DSA recipe, grouped by library: what broke, what we patched locally, and what we prepared upstream.

The FA4 Catalog on Blackwell: Variants, sm Guards, and Runtime Selection
Inside the Flash Attention 4 catalog MegaCpp ships: which kernel variants we keep, the sm_100 / sm_121a guards, the selection policy at runtime, and the validity checks that fail closed.

FIRE, DASH, ReDo in practice: cadences, shard safety, and when we turn them off
How this plasticity stack works in code: one-shot FIRE resets, periodic DASH and ReDo passes, shard-aware parameter surgery, and the training lanes where the toolkit is best left off.

FIRE, DASH, and ReDo as one plasticity toolkit
How three separate plasticity ideas fit into one toolkit, what the public samples actually show, and which design choices are worth preserving as the stack evolves.

Flash Attention 4 in practice: what we shipped and what we cut
Our hybrid stack's applicability matrix for Flash Attention 4, the validation profiles, the dense-full rollout gates, and the regressions that killed the first FA4 variants before they reached deployment.

FP8 in the training stack: what shipped and what we rolled back
An engineer's account of rolling FP8 through the training stack: DeepGEMM block-scaled GEMMs, torchao Float8Linear, TransformerEngine FP8-aware activation checkpointing, and the parts that looked good on paper but lost the benchmark.

Framework Survey: FSDP2 vs Megatron-Core vs DeepSpeed vs Torchtitan vs Nanotron vs MaxText
Honest comparison of large-scale training frameworks, what each is good at in 2026, and which stacks fit NVIDIA and TPU training lanes.

Hybrid FSDP/DDP on NVIDIA: Megatron DDP plus FSDP2 for the ensemble
How MegaCpp combines Megatron-Core DistributedDataParallel with PyTorch FSDP2 across H200 and GB10, the gradient-bucket sizing rules we ship, the freeze plan for the eight specialists, and the failure modes that defined the contract.

ZeRO-3-shaped sharding on the XLA backend: what transfers from FSDP2 and what does not
How to think about TPU XLA sharding honestly: keep the ZeRO-3 memory goal, drop the assumption that TPU uses the same eager FSDP2 wrapper model as CUDA.

FSDP2 pain and payoff: what actually reduced memory
A practical look at selective wrapping, reshard timing, mixed precision, and the interaction between sharding, pipeline boundaries, and heterogeneous model blocks.

Fused MLA on Hopper and Blackwell: projection, RoPE, and the KV cache that ships
The NVIDIA side of Multi-Latent Attention in the MegaCpp ensemble: a fused down-norm-up projection, a fused split-RoPE-concat Triton kernel, a compressed KV cache, and how it all lands on Megatron-Core.

Fused MoE and DeepEP on NVIDIA: the dispatch layer we ship
How MegaCpp dispatches MoE tokens on H200 and GB10: DeepEP NVSHMEM all-to-all on NVLink and IB, fused expert GEMM, expert sharding, drop policies, and how the kernel layer interacts with our eight-specialist routing.

Gated DeltaNet, hyper-connections, and DynamicTanh inside the hybrid stack
How Gated DeltaNet, cross-layer hyper-connections, dynamic tanh normalization, attention residuals, and gated attention compose inside the MegaCpp hybrid stack, what augments, what replaces, and what survived ablation.

Training the MegaCpp SLM Ensemble on GB10: a Grace Blackwell war story
Field notes from bringing the MegaCpp SLM Ensemble up on NVIDIA GB10 and DGX Spark: silicon surprises, NaN bisects that ate days, regressions caused by our own patches, and the software-stack choices that held.

Trajectory-straightness loss: span sampling, layer choices, and XLA-safe limits
How the STP-style trajectory-straightness auxiliary loss is implemented in the public sample, why it samples ordered triples instead of predicting future latents, and what the runtime should preserve.

Gradient Accumulation and Microbatching Under FSDP2: How We Stopped Guessing the Knobs
Microbatch sizing under FSDP2, accumulation boundaries that respect TP/EP/SP, loss scaling under FP16/BF16, and the tuning loop that finally converged on H200.

Graph recompilation hell: shape drift, graph contracts, and why TPU runs slow down without crashing
A walkthrough of the most common TPU recompilation failure mode: changing shapes, unstable graph contracts, and weak runtime discipline.

H200 Bringup and Naming: What Had to Be Made Explicit
A code- and doc-grounded look at H200 bringup, why naming mattered, how a flagship hybrid recipe was encoded across launch surfaces, and which infrastructure assumptions had to be turned into explicit contracts.

H200 Memory Geometry for the Hybrid Stack
How weights, gradients, optimizer state, activations, routing scratch, runtime reserve, and fragmentation stack up on one H200 device in a hybrid training stack.

How we keep a patch lane
The operational mechanics of running a hybrid Mamba-3 plus DSA recipe against a fast-moving stack: pinned environments, a small patch inventory, and a regular merge-back cadence.

Hybrid Layer Interleaving: Why A/M/E/R Schedules Need Real Execution Plans
A code-grounded explanation of how interleaved schedules work for NAM52 and NAM56R-style hybrid models, based on hybrid pattern notes, scheduling examples, and authoritative parallelism references.

Serving the eight: router, per-specialist scheduler, and the KV layout that keeps them honest
How we actually serve an eight-specialist C++ ensemble: a top-level router, per-specialist continuous-batch schedulers, paged KV per model, admission control, and the SLOs we publish.

Kernel Catalog and Impact: Why the Runtime Needed a Real Map
A grounded tour of the kernel catalog across attention, sparse MLA, MoE, MTP, and dispatch/combine paths, with emphasis on why naming the kernel family and backend contract changed system-level decisions.

Kernels that pay for themselves
Which custom kernels and fused paths in MegaCpp are worth their maintenance cost, which ones are borderline, and which ones belong behind a fallback or in experiments.
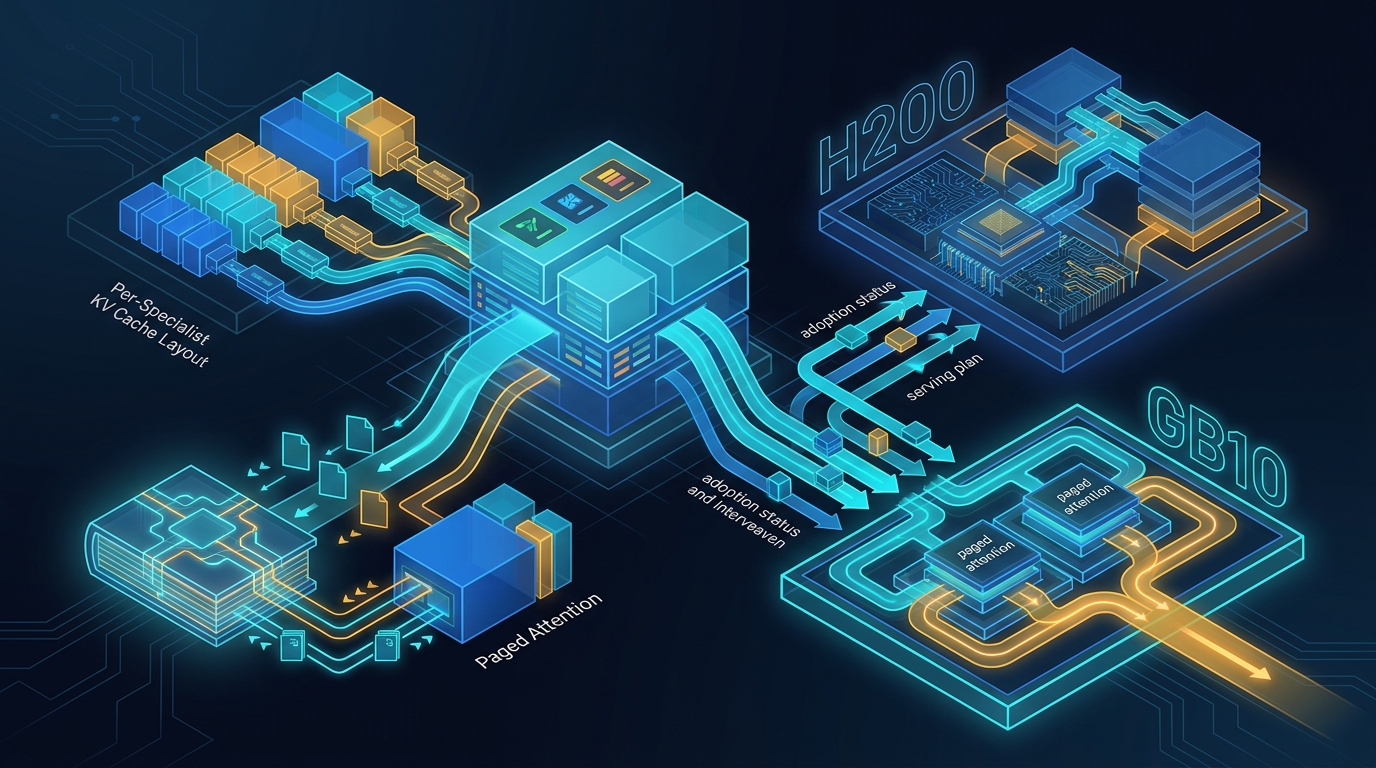
KV Cache and Paged Attention for the MegaCpp Specialist Ensemble
Per-specialist KV cache layout, MLA cache after weight absorption, paged attention adoption status, and what changes between H200 and GB10 - including the MegaCpp serving plan.

libtpu and JAX interaction: shared runtime, separate ownership
How PyTorch/XLA, JAX, PJRT, and libtpu relate on TPU without collapsing distinct layers into one vague runtime claim.

License Hygiene and Provenance for a C++ Training Corpus
How MegaCpp describes source provenance, revision pinning, SPDX metadata, and refusal-list rules for a public C/C++ corpus narrative without overstating legal certainty.

Long context and attention sinks: what actually held up past 16K
YaRN, RNoPE, packed-document masking, attention sinks, massive activations, and query-dependent output gating: a field report on which long-context techniques survived contact with the MegaCpp C++ corpus.

Loss Curves and the Divergence Playbook: How We Catch It at Epoch 0
The divergence playbook used on every training start: early-training spikes, NaN bisect, LR warmup shape, data-order suspects, and the monitors that catch it before step 100.

M2RNN and Engram: The Memory Subsystem Inside the Hybrid
Where matrix-state RNN layers, causal n-gram Engram branches, and the learned concept bank fit inside our Mamba 3 + Transformer hybrid — and which pieces remain useful in the public memory stack.

Mamba-3 fused trapezoidal scan on TPU v6e
How we took the Mamba-3 trapezoidal SSM update from a CUDA Triton kernel to a Pallas/XLA-friendly scan on TPU v6e, and what survived the deployment port.

Mamba 3 + Transformers: Why MegaCpp Uses a Hybrid Stack for C++
A grounded look at why MegaCpp combines Mamba-style state-space blocks with a smaller number of attention blocks for long-context C++ work, and which parts are design choice versus published literature.

The Mamba 3 Kernel Journey: CUDA, Pallas, TileLang, and an Honest Look at CuTe DSL
How the Mamba 3 kernel stack works in MegaCpp: TileLang on H200, Pallas on TPU v6e, a CuTe DSL port that was evaluated but not adopted, and what each attempt showed.

Mamba 3 Parallel Performance: Where It Beat Attention, and Where It Lost
MIMO scaling, chunk-size behavior, the PsiV cache trade-off, and an honest tally of where a Mamba 3 hybrid outran pure attention on NVIDIA H200 and where it did not.

Manual Splits and What They Cost
A grounded look at explicit pipeline boundaries, pipe-delimited patterns, weighted partitioning, and the maintenance cost of forcing stage shapes by hand in hybrid attention, MoE, and recurrent stacks.
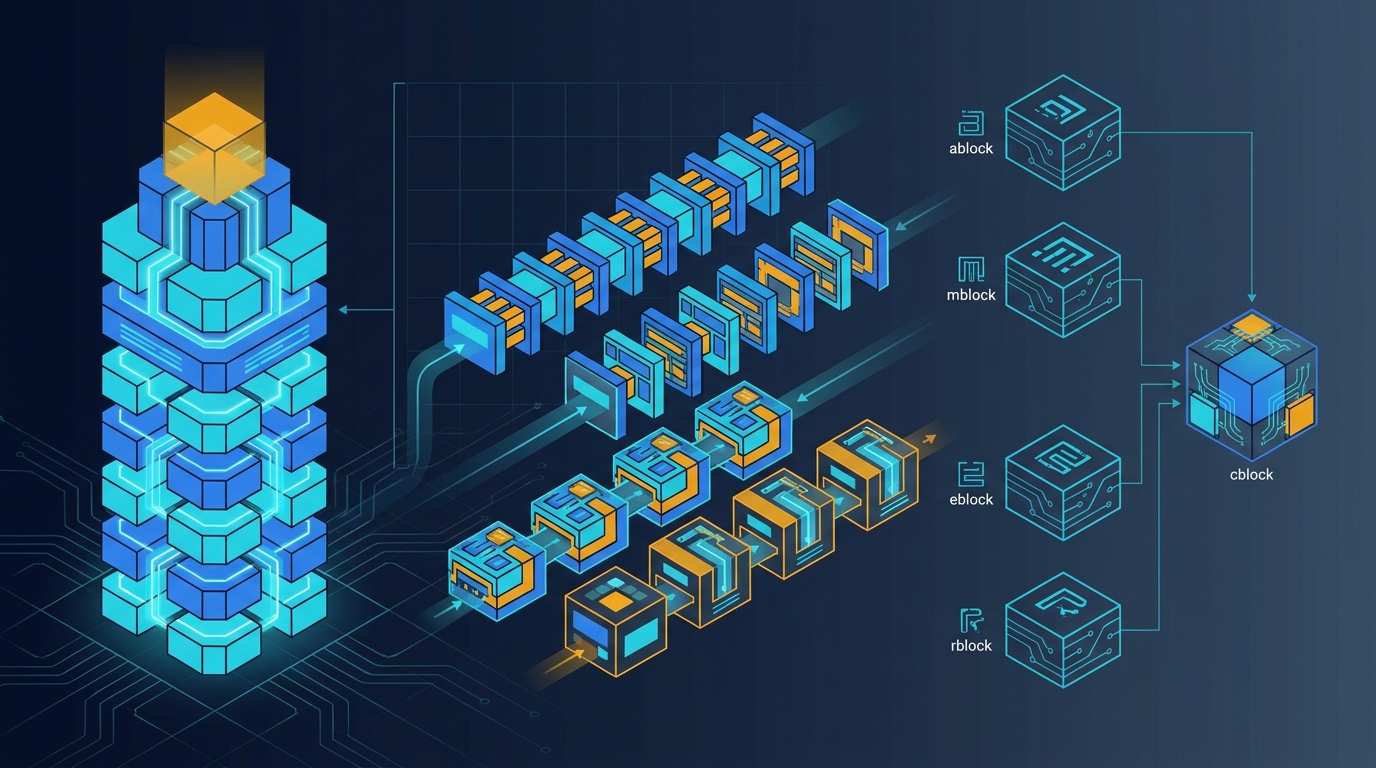
MegaCpp model glossary: patterns, blocks, and what names like NAM52 and NAM56R encode
A grounded glossary for MegaCpp model notation, hybrid layer patterns, and block-family names, tied back to live builder code, launch helpers, and regression tests in MegaCpp.
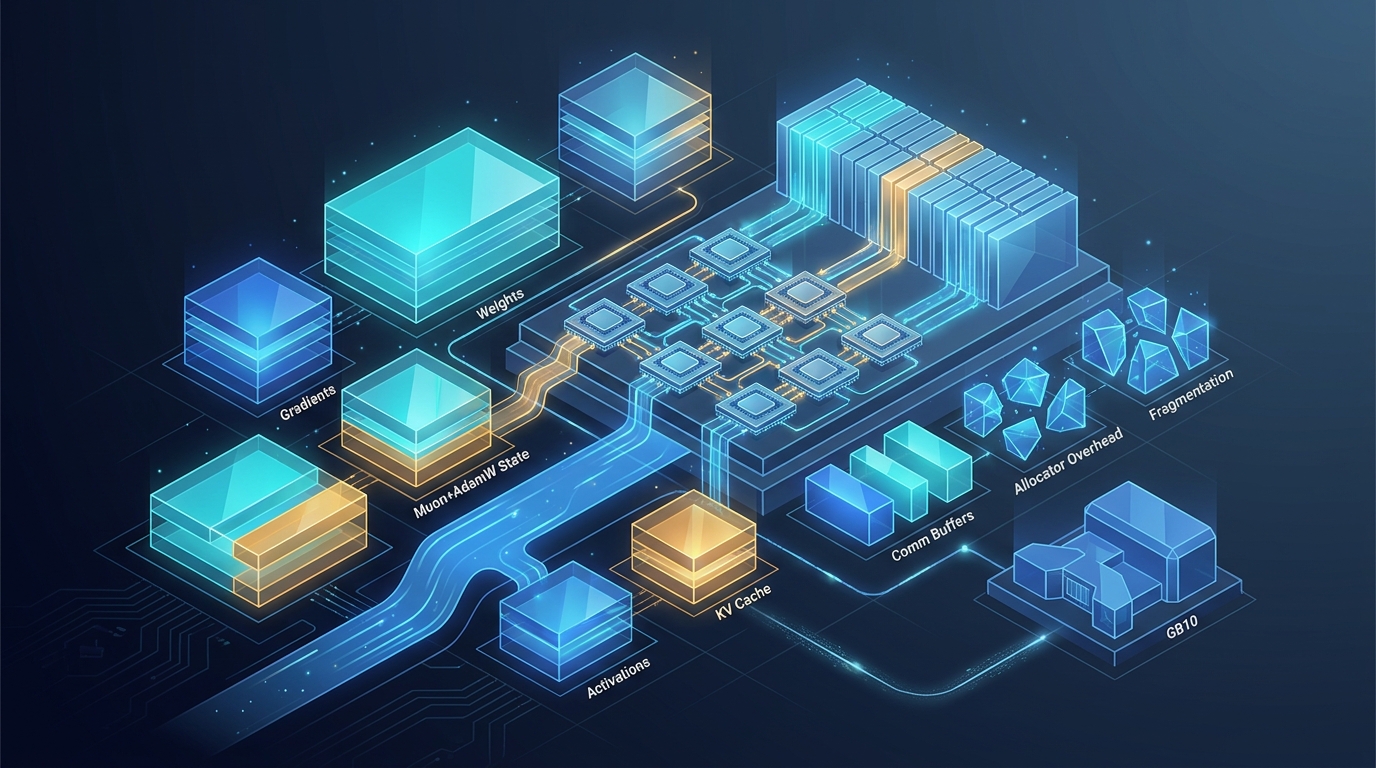
A Memory-Budget Anatomy for One Specialist on H200:8
Line-by-line breakdown of weights, gradients, Muon+AdamW state, activations, KV cache, communication buffers, allocator overhead, and fragmentation for a single specialist trained on 8x H200, with the GB10 contrast.

Multi-Head Cross fused on Blackwell: from reference einsum to Triton
How the MegaCpp Multi-Head Cross branch mixer went from a readable PyTorch reference to a fused Triton path on Hopper and Blackwell, and how it lands in deployment through a narrow feature contract.
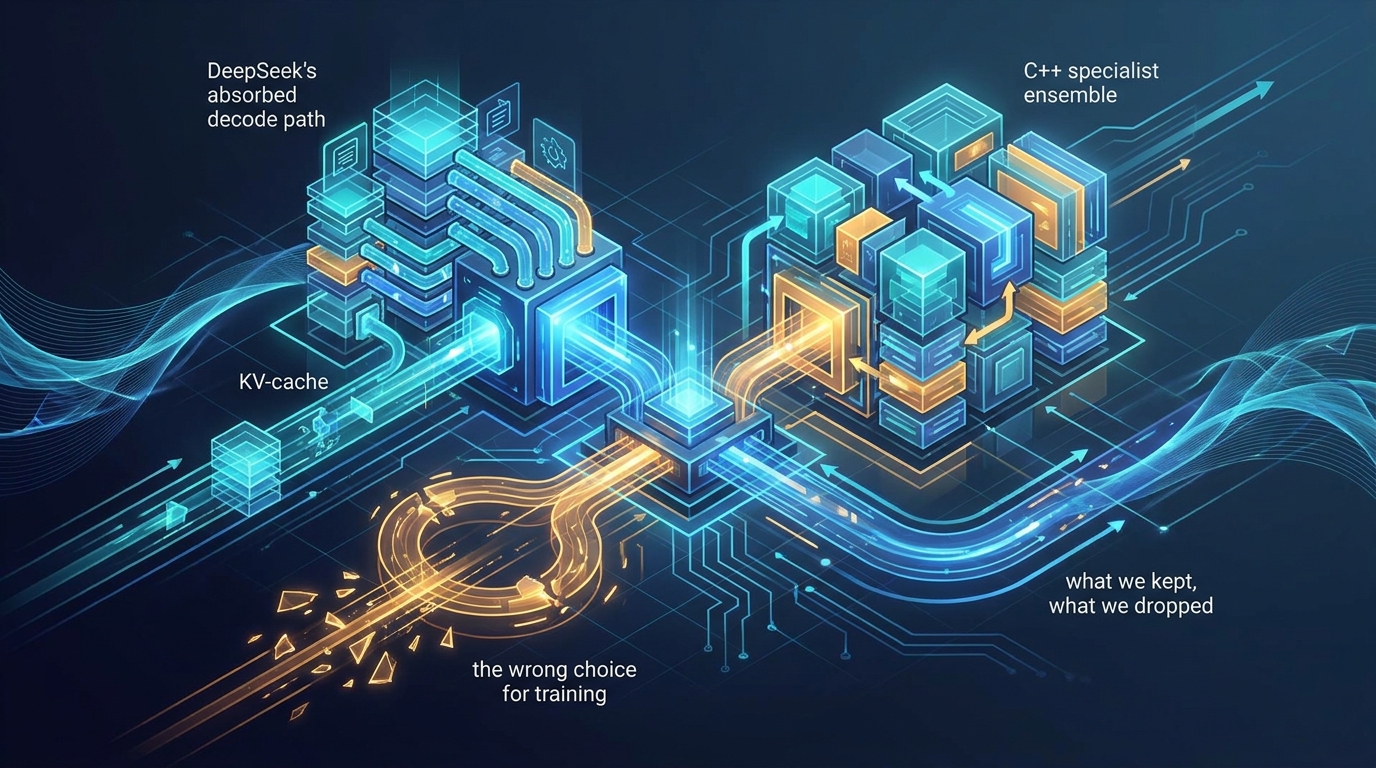
MLA weight absorption: what we kept and what we dropped for the C++ specialists
Multi-Head Latent Attention in production: why DeepSeek's absorbed decode path is the right choice for KV cache, why it is the wrong choice for training, and how the C++ specialist ensemble uses both.

MoD, MoDA, and MTP: Dynamic Depth and Multi-Token Heads
How we allocate compute per layer with Mixture-of-Depths, cross-attend across layers with MoDA, and train multi-token prediction heads that double as a draft source for self-speculative decoding.

Modal Benchmark Receipts: What Counted as Evidence and What Did Not
A grounded guide to benchmark receipts using compile posture, backend identity, and narrow evidence records rather than headline throughput claims.
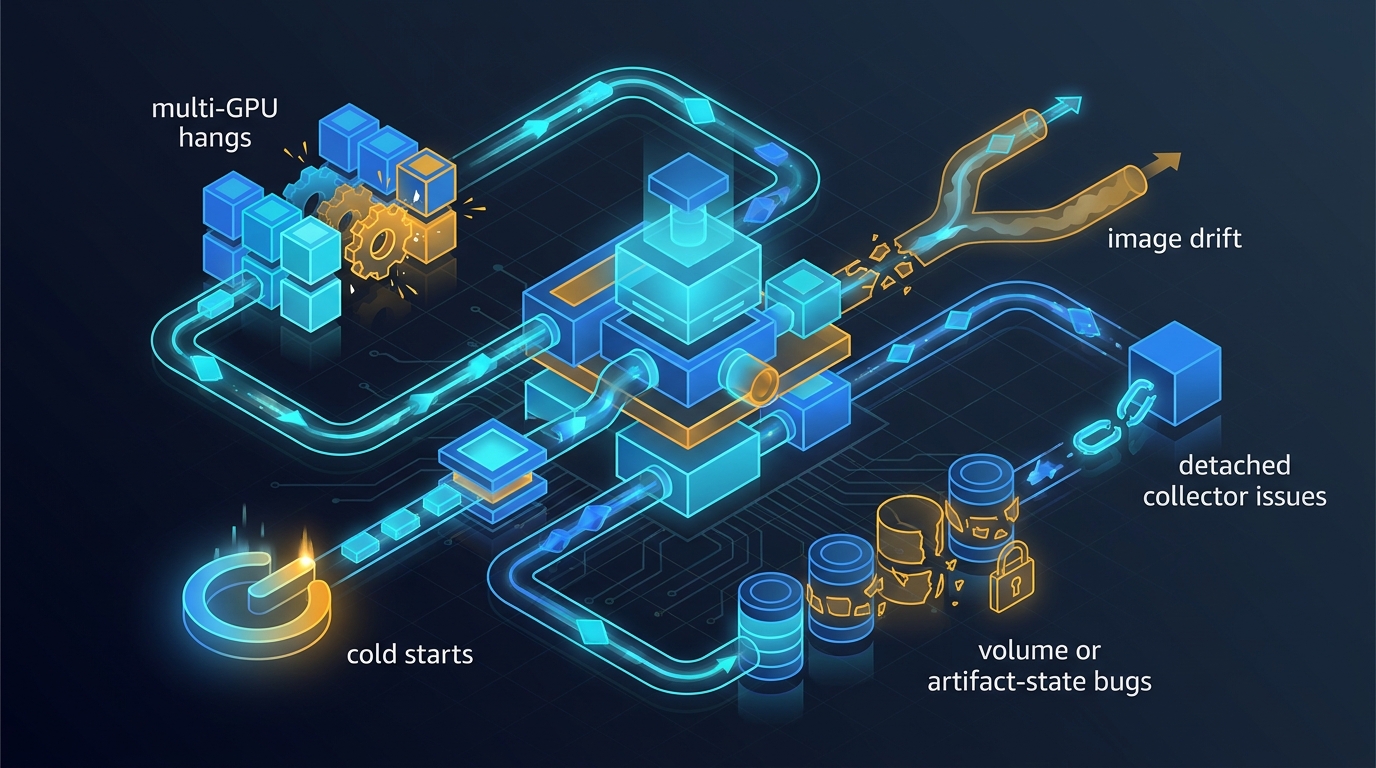
Modal Debugging Guide for Training and Benchmark Failures
A grounded guide for debugging Modal failures in MegaCpp: cold starts, multi-GPU hangs, image drift, detached collector issues, and volume or output-state bugs.

Modal image construction and the cold-start tax we actually pay
How we layer the Modal training image, why every wheel is pinned to the training stack, how persistent volumes absorb the inductor-cache hit, and the 30-90 second startup tax we accept as the price of burst compute.

Modal Multi-GPU Pain and the Fixes That Actually Landed
NCCL topology, GPU isolation, eviction and OOM-kill behavior, observability gaps, and the guide we follow when a Modal multi-GPU job hangs on the first forward pass.

Modal Training Platform Overview
Why we use Modal for ad-hoc training and benchmark jobs, how the image, GPU, volume, and secret model is wired, and when Modal wins against reserved H200 or TPU capacity.

Modal vs Owned H200:8 vs TPU: Which Surface We Use and Why
How we decide between Modal, reserved H200:8 hosts, and TPU slices based on operator overhead, latency to first useful step, benchmark hygiene, and failure isolation.

The MoE Routing We Actually Shipped
Token Choice vs Expert Choice, null-expert debugging, gating stability, and the production routing decisions behind the MegaCpp SLM Ensemble.

Benchmarking the MegaCpp stack on Modal: multi-GPU lessons from rented boxes
What we learned running the training stack on rented H100, H200, and B200 boxes through Modal: three benchmark lanes, an 8-GPU FSDP2 hang, and the bookkeeping that lets the numbers survive a week.

Muon on Hopper and Blackwell: The NVIDIA Lane of the MegaCpp Optimizer Stack
How Muon, MuonClip, and the QK-clip family get from a single-file research implementation into a production AdamW-coexistent optimizer path for the MegaCpp ensemble on H200 and GB10.

NCCL and collective hangs: the H200 multi-host timeout playbook
Allreduce stragglers, NCCL deadlocks, P2P env vars, ibverbs quirks, and the liveness/timeout playbook we run on MegaCpp's H200 multi-host CUDA lanes.
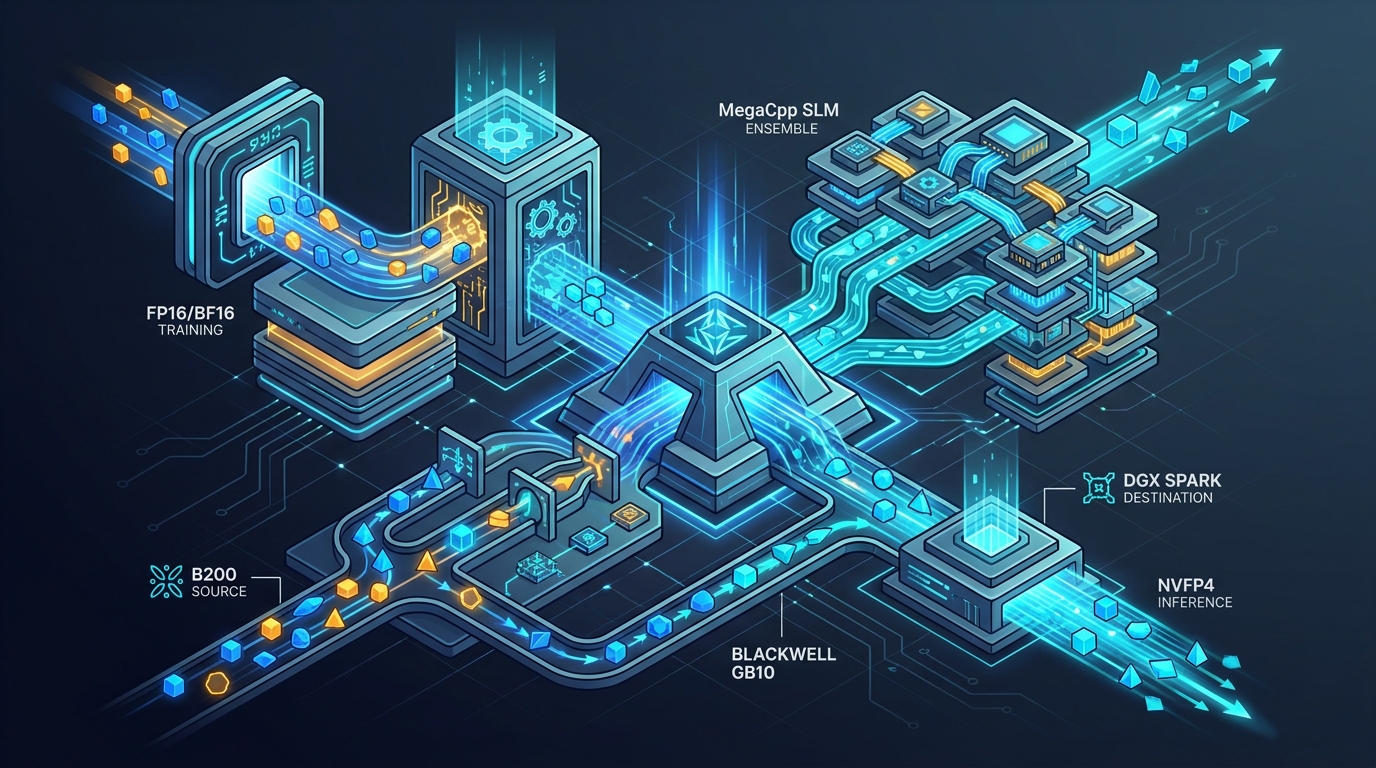
NVFP4 Inference for the MegaCpp SLM Ensemble
Why we train in FP16/BF16 and ship in NVFP4, what Blackwell and GB10 actually give us, and which kernels survive the trip from B200 to DGX Spark.

Observability and the Three Dashboards We Actually Live With
Metrics, traces, and the training / infra / serving dashboard layout that keeps an eight-specialist C++ ensemble debuggable at 3am.

One morning of bugs
A real morning's worth of upstream-library breakage during a training wave, and the operational stance we landed on: keep a patch lane and upstream the fixes once they are ready.

OOM Debugging Playbook for H200 Training Runs
A practical playbook for triaging H200 out-of-memory failures: distinguish fragmentation from true exhaustion, isolate the largest activation surfaces, and apply the cheapest fix first.

OOM on v6e: Why Memory Pressure Looked Different on TPU
What TPU v6e out-of-memory failures taught us, why the obvious fixes were often wrong, and how the lane eventually measured memory honestly.

Pallas FlashAttention with logit softcap on TPU v6e
Why softcap attention on TPU needs a dedicated kernel surface: fuse the nonlinearity, keep masking contract-friendly, and avoid turning a stability trick into a second full pass over the score matrix.
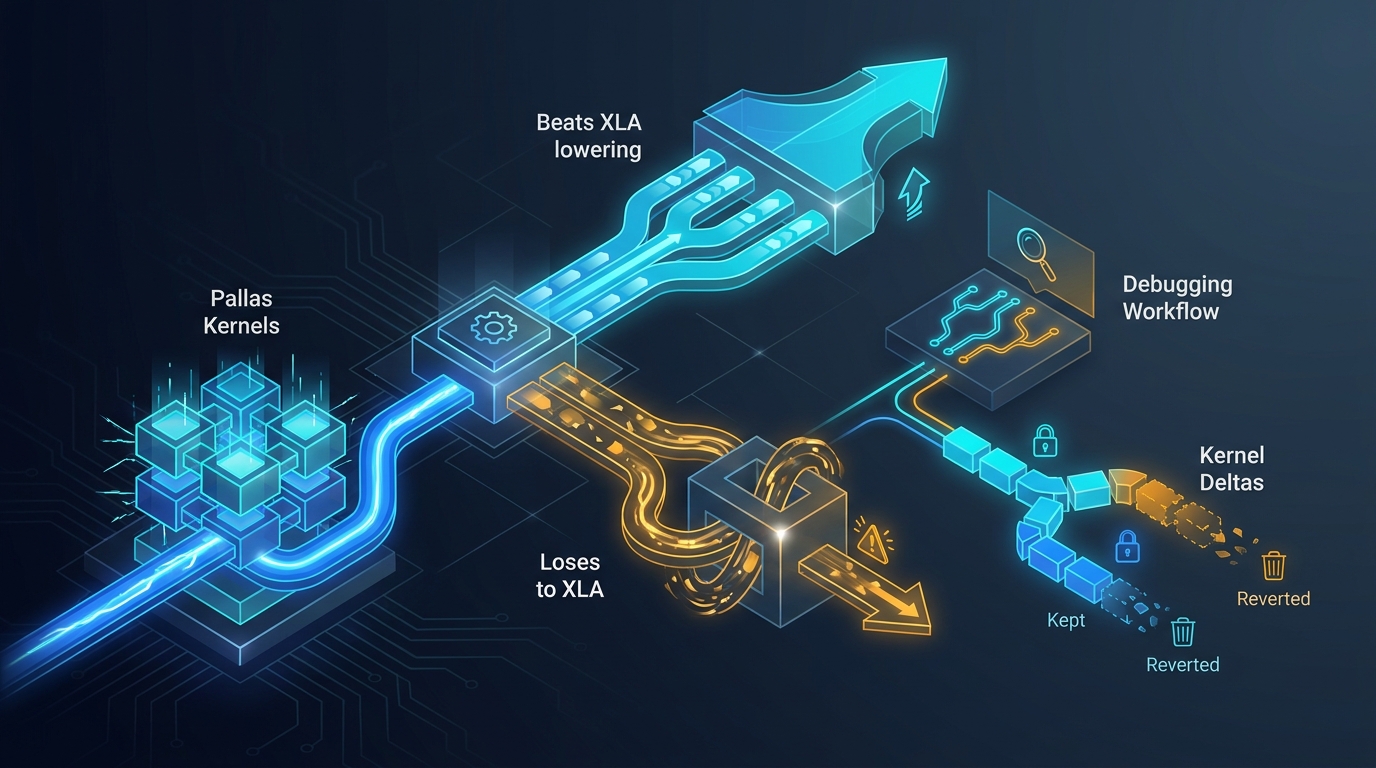
Pallas kernels on TPU v6e: what we ship and what we deleted
Where Pallas beats the XLA lowering on TPU v6e, where it loses, the debugging workflow that keeps us sane, and the kernel deltas we kept versus the ones we reverted.
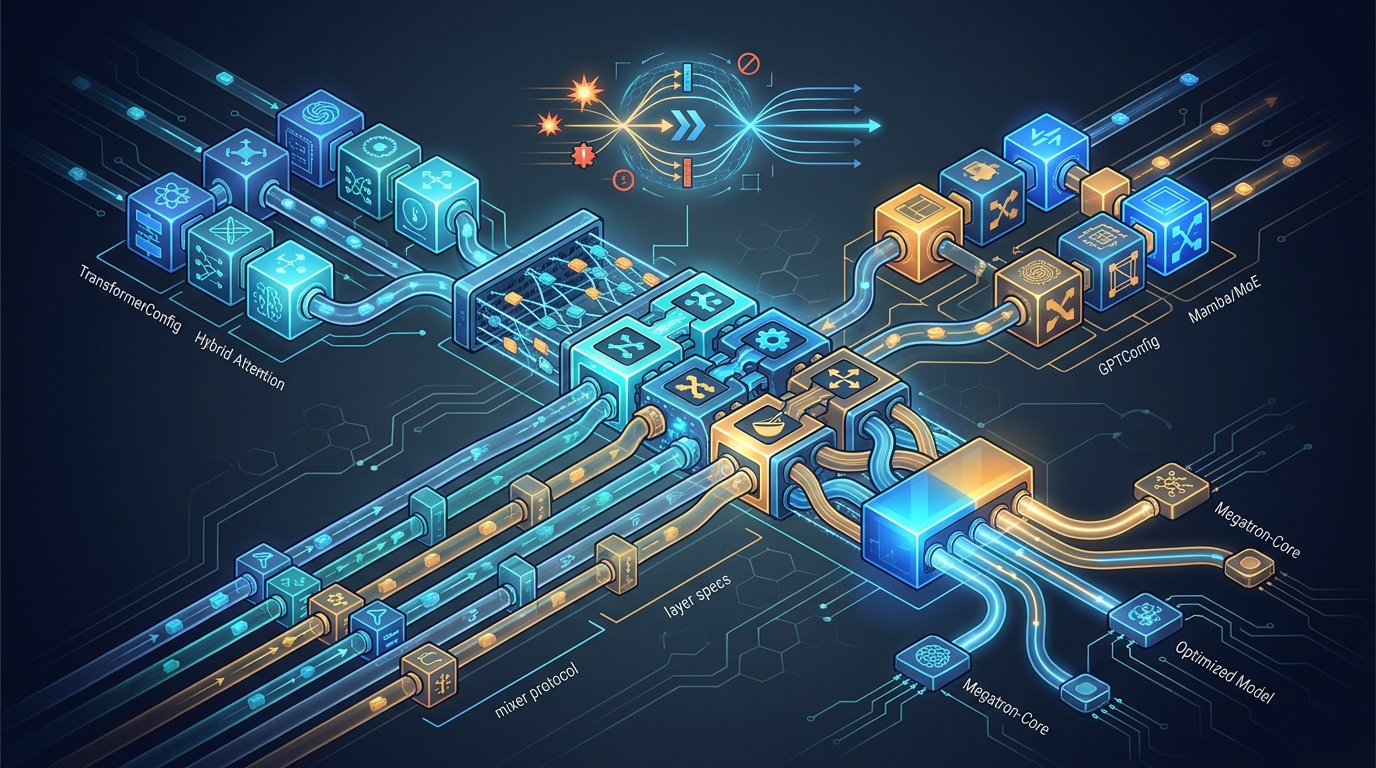
Porting To Megatron-Core Is Harder Than It Looks
Why lifting a hybrid attention/Mamba/MoE stack into Megatron-Core is a multi-adapter exercise: base config mapping, layer specs, mixer protocol, and the bridge layer that makes them line up.

The MegaCpp precision recipe: FP16, BF16, FP8 and NVFP4 in one stack
How MegaCpp picks a numerical format per op, per device, and per phase: FP16 only as a floor, BF16 as the steady state, FP8 in selected GEMMs, and NVFP4 for Blackwell inference.

Profiler and performance reports: making benchmark runs comparable months later
How MegaCpp samples training, what a structured performance report should contain, and how observability stays bounded so measurement does not become the regression.

Profiler-Guided Optimization: Start With the Runtime Story, Not the Theory
A grounded guide to profiler-led optimization using the reports, code comments, and configuration surfaces in the MegaCpp repos.

Sequence, Context, and Expert Splits in the Hybrid Stack
A concrete guide to what SP, CP, TP, and EP actually touch in the hybrid training stack, what communication each one introduces, and what each split is structurally forbidden from touching.

SLM architecture in MegaCpp: hybrid patterns, block ownership, and why the letters matter
A grounded architectural read of the MegaCpp small-model stack: hybrid patterns, block semantics, schedule ownership, and why names like ablock, mblock, and eblock are operational rather than decorative.

SLM data: what the pipeline optimizes for and why the loader contract matters most
A grounded walkthrough of the MegaCpp data path: parquet shards, split logic, packed rows, metadata columns, and the interface choices documented in the public sample corpus.

SLM training in MegaCpp: what the stack optimizes for and what stays explicit
A grounded walkthrough of how the project approaches small-language-model training: explicit stack specs, memory-first patches, hybrid blocks, and auxiliary losses that stay under runtime control.

SOTA Ablation and Comparison: How MegaCpp Decides What to Keep
The ablation plan, the comparison methodology, and the honest numbers behind the MegaCpp SLM stack — what stacked, what didn't, and what we threw out even though the paper said it would help.

Specialists: What the Expert Path Actually Changed in the Stack
A grounded look at specialist or expert paths using the real routing flags, expert-parallel notes, and standalone MoE receipts from the codebase.

Speculative Decoding Inside an Eight-Specialist Ensemble
Drafter choice, acceptance rates on real C++ workloads, and the failure modes we hit adapting speculative decoding to an ensemble of specialists.

STP after ten thousand steps: what changed, what we watched, and what stayed the same
What the STP-style auxiliary loss can change once a run is past the early warmup window: the hidden-state straightness signal we monitor, why the main loss still dominates, and which parts of the baseline recipe stay intentionally unchanged.

Semantic Tube Prediction: the 10K-step gate, trajectory straightness, and the wiring mistakes that mattered
A grounded walkthrough of the STP-style auxiliary loss: the public sample, the multi-span and multi-layer variants, the 10K-step gate, and the integration mistakes that can quietly disable it.

Structure Embeddings and Relation Bias: Teaching the Model That Code Has Shape
How per-token structure IDs, chunk boundaries, and call/type edges become input embeddings and attention bias in the MegaCpp stack, what the ablations kept, and what ships in deployment.

Transformer Engine replacements on TPU: keeping one model definition across paths
Transformer Engine is an NVIDIA Hopper and Blackwell story. On TPU v6e it does not exist. This is the layer-spec abstraction and the XLA-friendly substitutes that let one model definition ship across both paths.

Tensor Parallel and Sharding: What Actually Splits, What Still Stays Global
A code- and doc-grounded walkthrough of tensor parallelism in public hybrid recipes, including where TP helps, where it does not, and how it fits into hybrid NAM52 and NAM56R workloads.

Throughput vs quality knobs: which trade-offs are real
A grounded map of the knobs that actually move the throughput-quality frontier in hybrid NAM52 and NAM56R training, based on public code, articles, and upstream references.

Tokenized enriched packed rows on TPU: feeding structure to XLA without recompiles
How the v6_enriched packed-rows pipeline feeds per-token structure IDs, chunk boundaries, and call edges into the XLA dataloader on TPU v6e without triggering compile cache misses, and how that contract lifts into the main path.
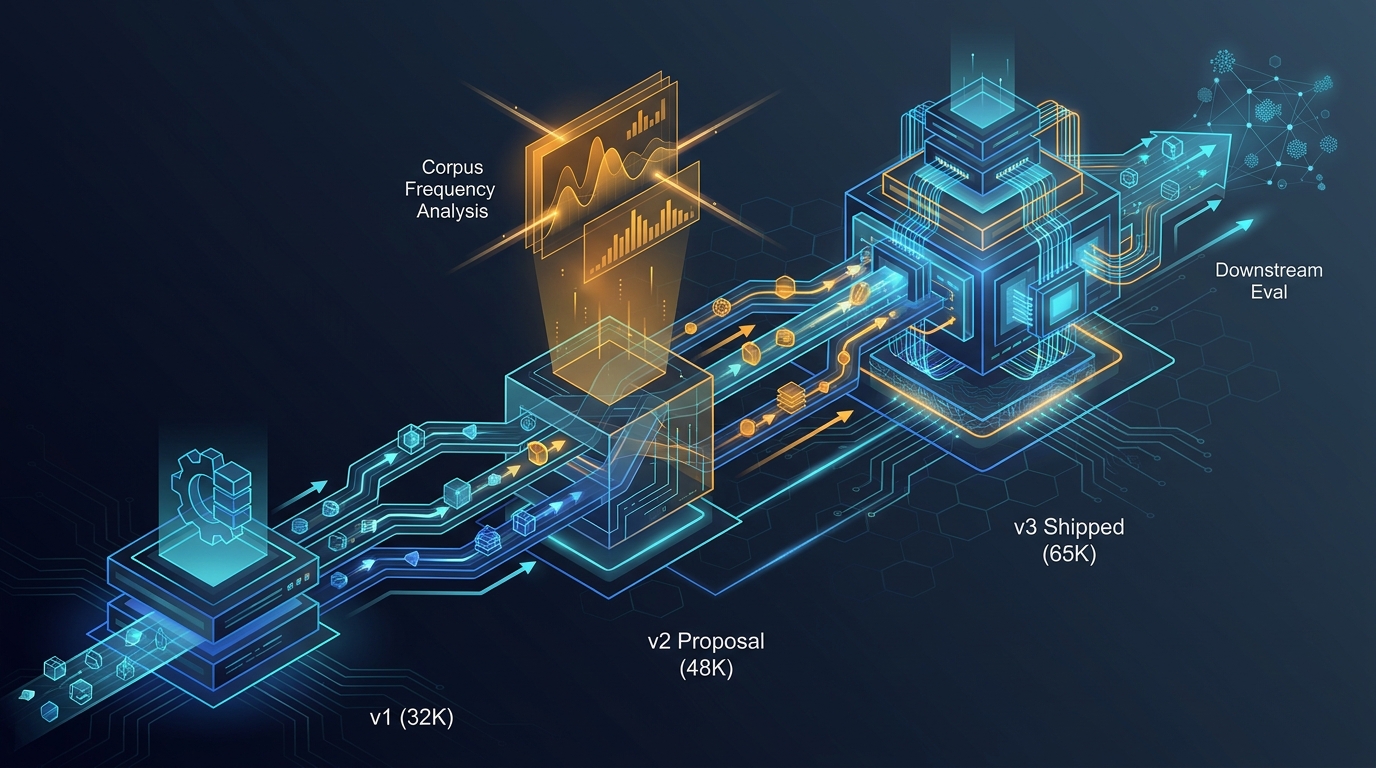
Tokenizer evolution for C++ code: from v2 proposal to v3 shipped
How the MegaCpp C++ tokenizer evolved from a 32K v1 through a 48K v2 proposal to the 65K v3 release: what we proposed, what corpus frequency analysis told us, and what it did for downstream eval.
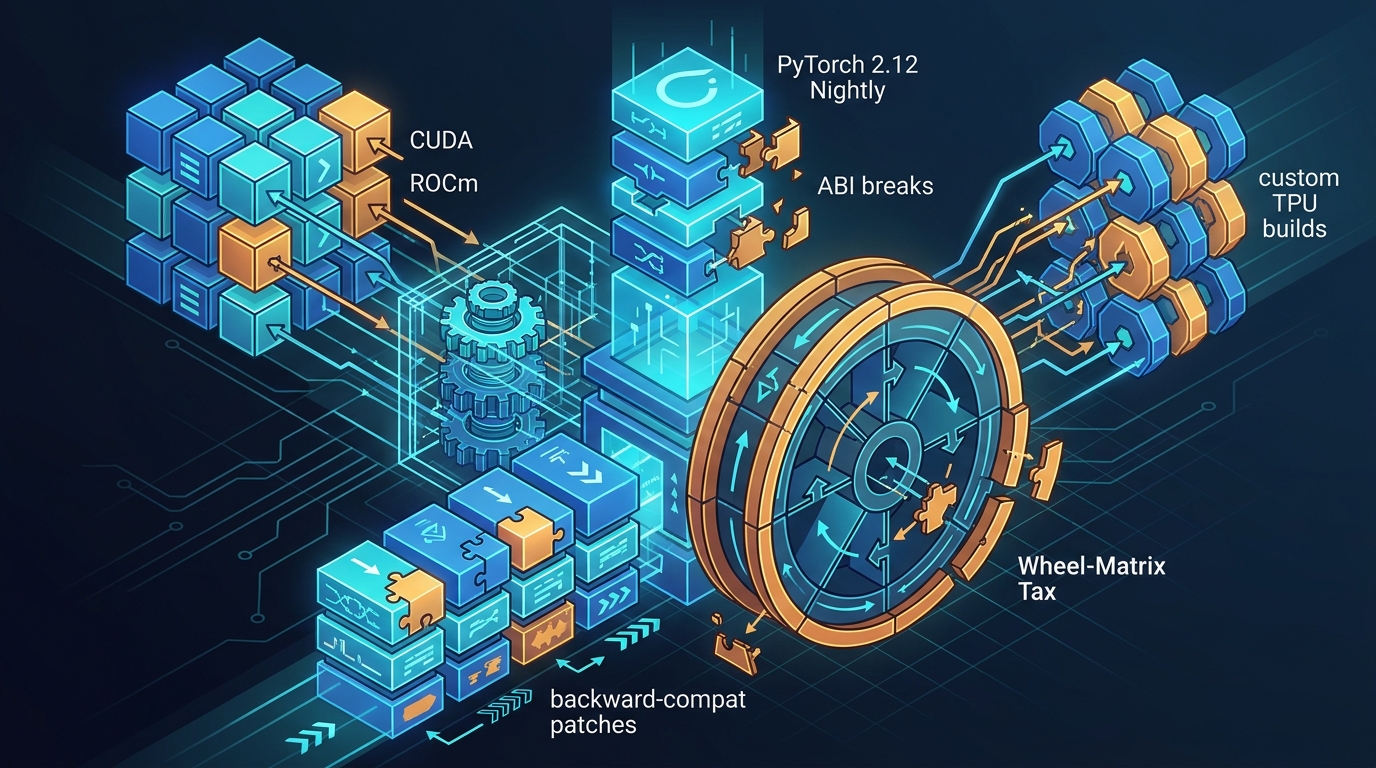
The Torch 2.12 journey: compile policy, runtime truth, and why version bumps were the easy part
Why framework upgrades in a hybrid training stack are really about re-validating compile behavior, sharding contracts, and backend-specific assumptions.

Torch 2.1.2 Nightly Wheel Matrix: What Actually Matters
Why wheel choice affects compiler behavior, device support, and backend viability more than most installation guides admit.

Torch XLA and PJRT reality: what actually matters
A grounded look at the current TPU stack: PJRT contracts, SPMD setup order, reduction semantics, and the failure modes that still shape training and evaluation.

TPU v6e Host Bringup
What makes a TPU v6e host bringup credible: pinned setup, environment restore, validation ladders, and durable runtime notes.

Training on 8x H200 SXM: the operator playbook
End-to-end operator notes for driving an 8x H200 SXM node: topology, NCCL tuning, storage layout, and the invariants that keep a run from silently drifting.
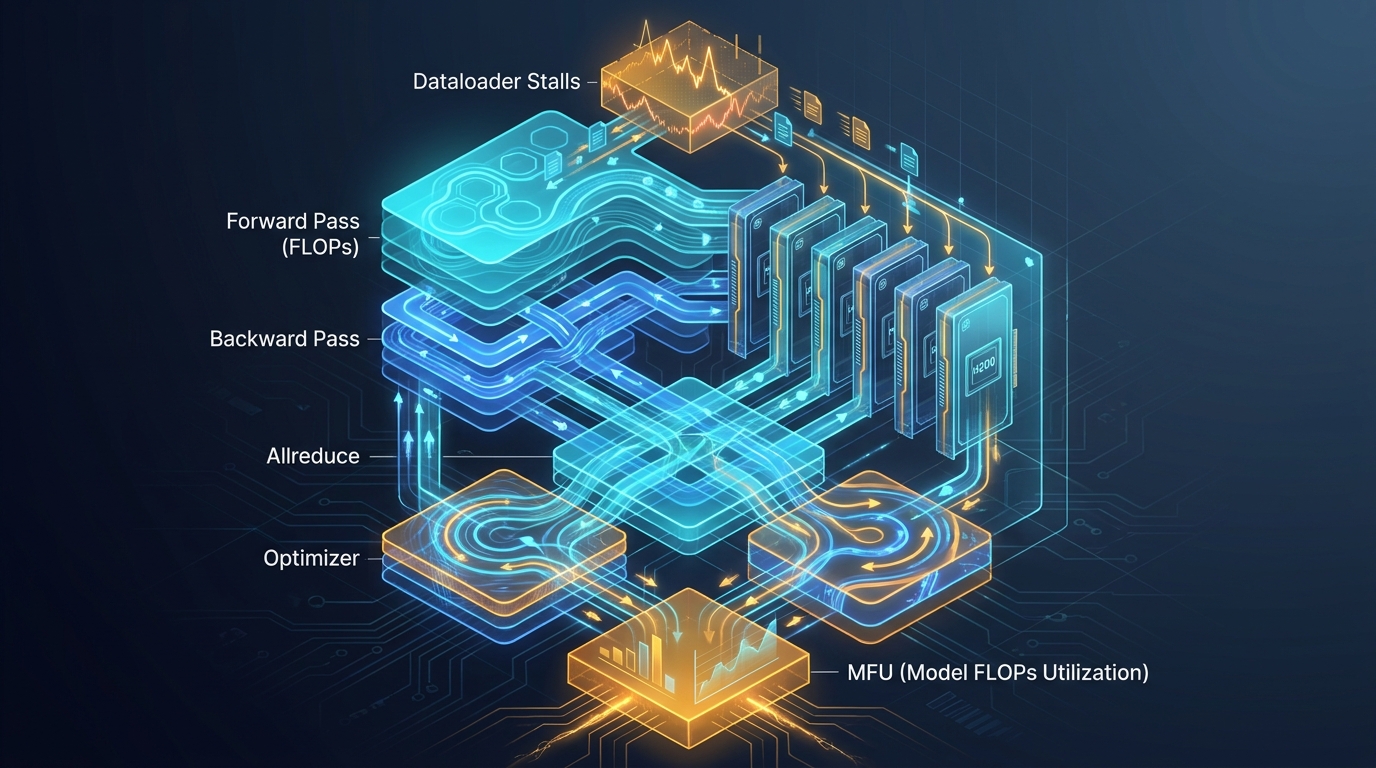
Training speed anatomy on H200
What actually sets training speed on H200 in public MegaCpp reporting: compile warmup policy, block mix, memory shape, and why local wins often fail to move whole-step throughput.

Training speed by feature: which parts of the stack really move step time
A grounded feature-by-feature look at training speed across a modern hybrid stack: Mamba fused paths, memory-traffic cleanup, MLA pieces, MoE dispatch, routing bridges, and feature taxes that should stay experimental.

Transformer Engine on H200 and Blackwell-class GPUs: the bridge we use
How MegaCpp wires NVIDIA Transformer Engine into the training stack on Hopper and Blackwell, where TE replaces native PyTorch layers, the FP8 interaction, and the fallback path that keeps non-NVIDIA lanes alive.

The Triton Kernels We Actually Maintain In-Tree
Which custom Triton kernels we keep in the training stack, how we autotune them without getting burned, and the numerical tests that keep us honest.

Unique additions and why they exist
A grounded map of the additions that exist because hybrid NAM52 and NAM56R training asks for them: pattern-aware layout code, hybrid embedding surfaces, targeted plasticity tooling, recurrent mixers, and runtime seams that keep them auditable.

Upstream PRs we wrote for Mamba-3, Sparse-MLA, Liger and DSA
A focused walk-through of the Mamba-3, Sparse-MLA, Liger-Kernel and DSA upstream PRs we have prepared: the bug, the fix, and where each one currently sits.

Upstream PRs we wrote for TileLang and Megatron-Core
A focused walk-through of the TileLang and Megatron-Core upstream PRs we have prepared: the bug, the fix, and what each contribution unblocks in our training stack.

Upstream PRs: how a small training shop ends up patching everyone else's libraries
A guided tour of the upstream contributions we are submitting back to the open-source training stack, the cadence we hold ourselves to, and the categories that keep showing up.

TPU v6e Performance Deep Dive: Real MFU, Sharding Topology, and the Things That Pretended to Help
How a TPU v6e lane actually spent time, why topology and compile amortization mattered so much, and which optimizations did not survive measurement.

Verifier-first C++ evals: why compile-and-test owns the metric
What the C++ evaluation stack teaches about deterministic extraction, sandbox contracts, pass@k, and why benchmark tables only become trustworthy after the verifier owns the pass label.

What Megatron Can and Cannot Split
A grounded look at split-friendly and split-hostile model surfaces: TP, SP, PP, EP, recurrent state, side embeddings, and why some boundaries remain architectural rather than automatic.

Why a 4B-8B model fills an H200 and still OOMs
A detailed accounting of where 141 GB of HBM goes when you train a 4B-8B hybrid Mamba 3, Transformer, and MoE specialist: parameters, gradients, optimizer state, activations, KV cache, MoE routing buffers, and allocator fragmentation.

XLA-safe AdamW and TPU runtime flags on v6e
How to keep optimizer math graph-friendly on TPU, treat runtime flags as explicit launch policy, and recalibrate after stack changes.

XLA SPMD sharding annotations we actually rely on
Why explicit mark_sharding annotations matter on TPU XLA, what should be pinned explicitly, and why propagation is not a substitute for a stable sharding contract.

Vocab and Tokenizer Plumbing on TPU: What XLA SPMD Makes You Decide Up Front
Vocab-size constraints under XLA, the padding choices that keep the compile cache stable, sharded embedding init under SPMD, and the per-specialist platform vocab story.

XLA vs CUDA: The Decision Matrix For Our Two Training Stacks
Where we keep one model definition, where the kernels diverge, what determinism we can give on each, how comms differ between NCCL and XLA collectives, and the operator surface that has to stay portable.